Content Catalogue too Big to Migrate to Cloud? Try Snowballs, Really
One of the principal perceived barriers to migrating a content catalogue to ‘the cloud’ is the size of the data and therefore the time it will take to ‘upload’ the material. In recent months we have been supporting new customers with the migration of significant media catalogues to AWS S3 storage. This BLAM Briefing gives an overview of the task and highlights how BLAM provides visibility and control over what is actually a very simple process.
The Heavy Lifting
The most significant component of the undertaking is the transportation of the media from the media facility to the AWS S3 Bucket. Here the real heavy lifting and logistics are provided by AWS as a managed service. As their diagram below suggests, it is extremely straightforward.
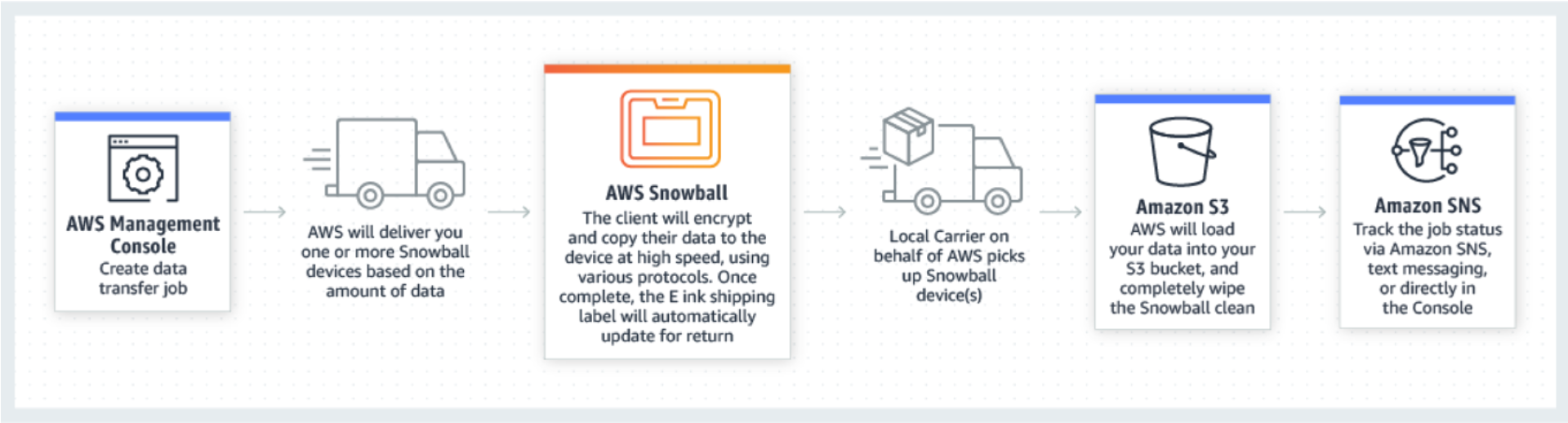
AWS Snowball managed service workflow. Copyright Amazon Web Services: https://aws.amazon.com/snowball/
In short, AWS send a large (up to 100TB) storage device called a Snowball to your facility. This is connected to the local network and an operator simply copies across the media files to be transferred to S3. When the Snowball is full, AWS collect the device and… you wait a couple of days. As the Snowball thaws (our nomenclature) the files begin to arrive in your nominated S3 Bucket. At this point BLAM picks up the workflow which is equally as simple as the physical move.
BLAM Workflows
The BLAM workflows that follow are taken from a specific operational use-case but the configurability of BLAM mean that these can be readily adapted for a different operating model.
Ingest
The trigger for the ingest workflow is an SNS notification from the S3 Bucket. This alerts BLAM to the presence of a new file in the Bucket. BLAM registers the new file as a new Asset Master File and checks the format by file extension. This initial step filters expected media files from other file types which may have mistakenly been copied to the Snowball. The next check is full inspection of the media file by the ‘Get Technical Metadata’ BLidget, this reads in technical detail such as resolution, frame rate or audio track layout and stores this in BLAM as technical metadata against the Asset File. The ingest status of the file is set to ‘Received’ and the next workflow is triggered.
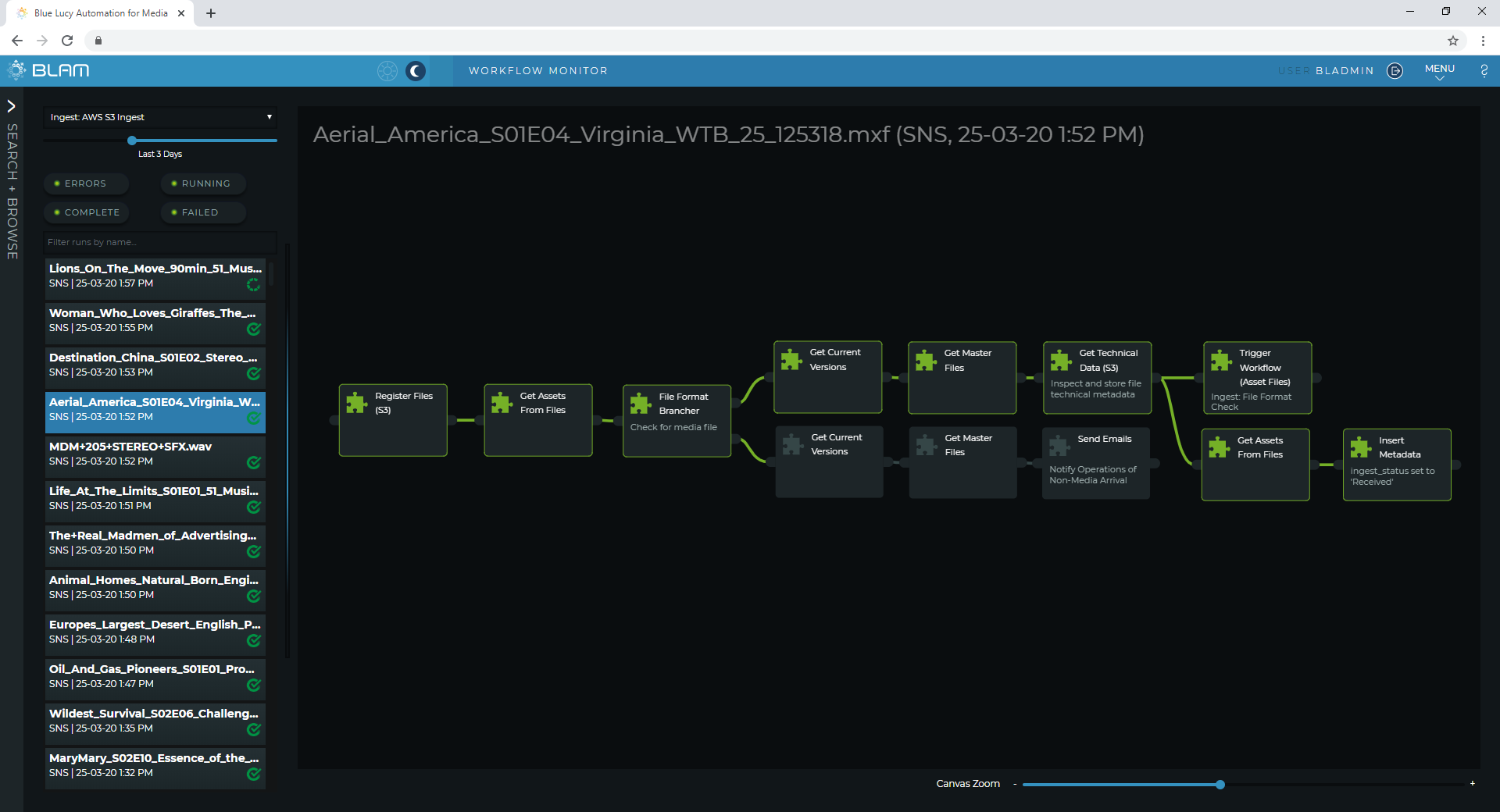
BLAM Workflow monitor showing automated ingest triggered by AWS S3 SNS notifications. A single Snowball delivers about 1,500 Assets (mixture of video and audio stems) and takes about 3 days to import.
Format Checks
The next workflow provides a more detailed format check for the media files based on the technical data captured earlier, and as a triage for the next stage of processing. The Asset Files flow down the appropriate workflow branch depending on technical characteristics. The ‘File Format Brancher’ BLidget separates the files based on extension and in this case separates video files, audio files, subtitle files and archive files (.zip and .tar). The video files undergo further checks to ensure that they meet known ‘broadcast’ formats based on resolution and frame rate. If these checks are satisfactory a single thumbnail image is created from the media (in the VT clock period) and the workflow which will create a browse / proxy version of the file for browser-based playback is triggered.
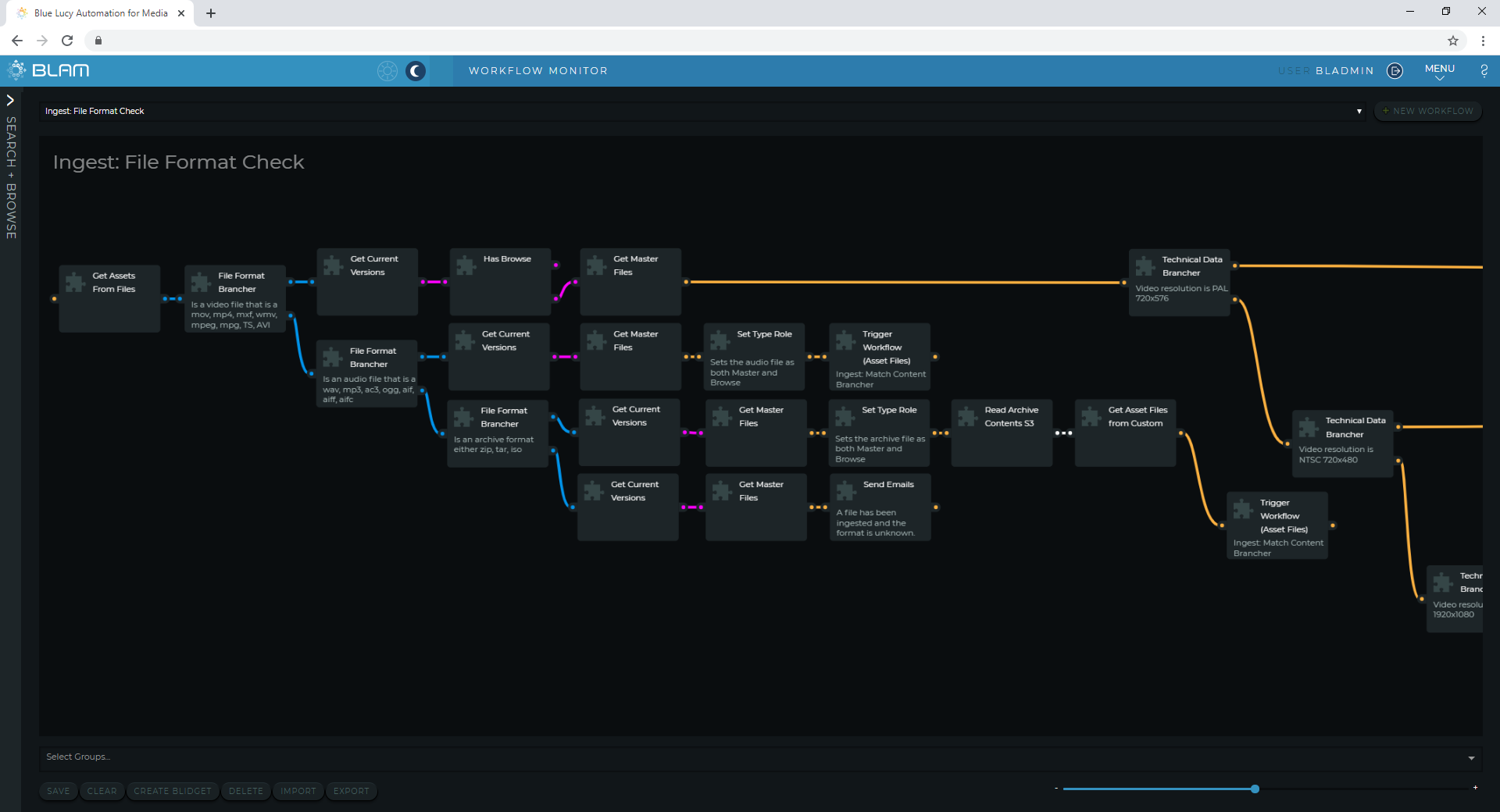
BLAM Workflow builder showing part of the file format check and triage workflow
Audio files are also inspected but, as these are typically playable in a web-browser, there is no need to create a proxy of these. Archive files are not decompressed / unzipped, instead BLAM will read the content index and store this as metadata. Additional workflows can un-zip these if necessary, at a later stage. For subtitle files, BLAM creates a Web-VTT version of these and assigns this as the ‘Browse’ version of the subtitle – this will allow subtitles to be visualised in the BLAM video players.
Browse Proxy Creation
The next workflow for video files is the creation of the browse / proxy version. This is the media Type that will be used in the BLAM video players. This operation uses the AWS Elemental MediaConvert service for this function. BLAM manages the process in a workflow which determines the audio arrangement in the Master file and ensures that a suitable MediaConvert Template is called. The objective is to create a browse file with an audio arrangement which matches the Master but with the audio tracks split by channel so that an operator can listen to each audio channel individually. MediaConvert is as good as any high-end transcoder available and the multiple queue mechanism allows BLAM to keep up with the media incoming from the rapidly thawing Snowball. Using MediaConvert also means that the Master files remain in place on the S3 storage which is time and cost efficient. We will cover AWS cost tracking in a future briefing.
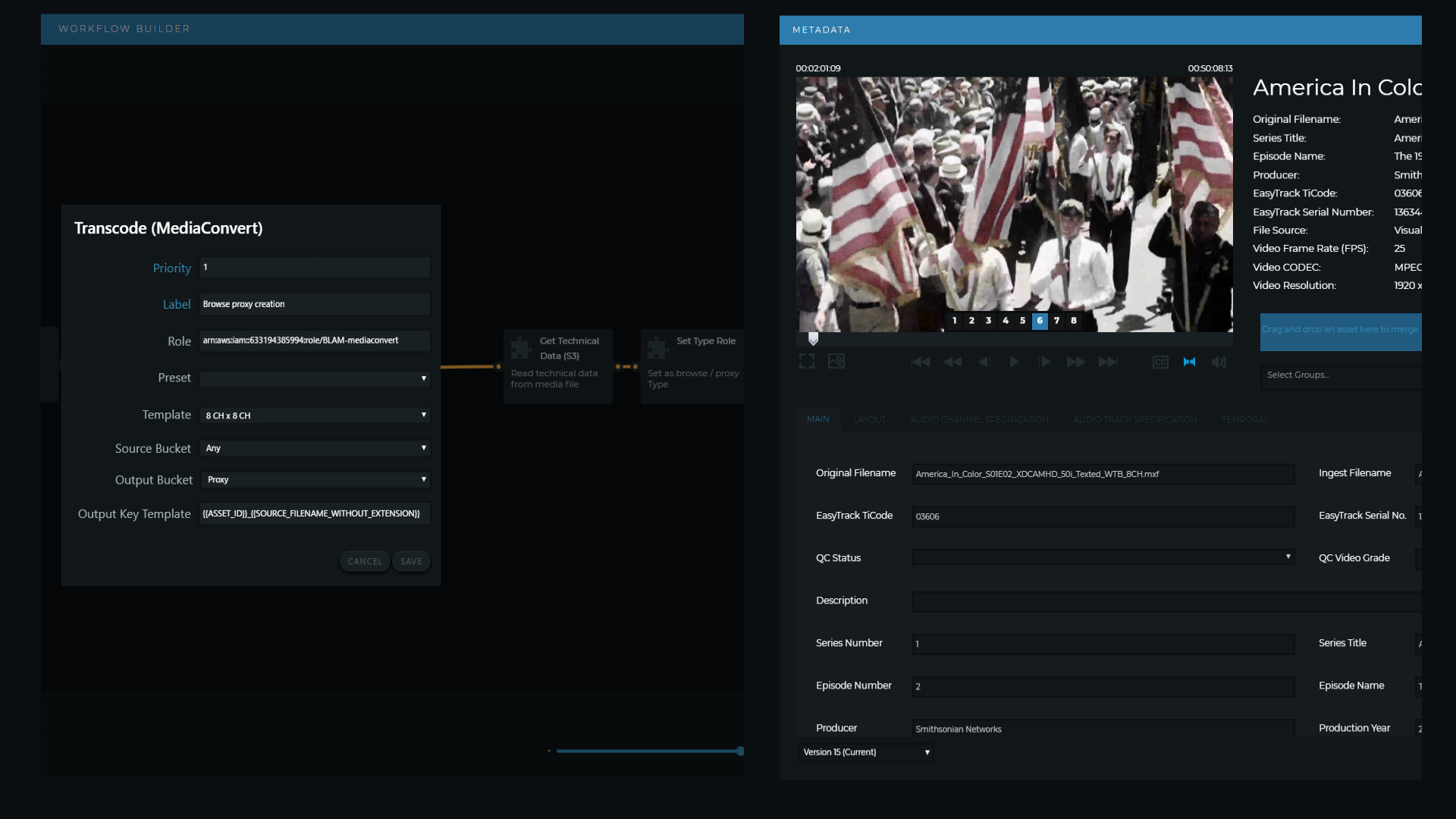
Setting a split track audio for the browse in the MediaConvert Template (left) allows individual channel monitoring in the player (right).
Archiving – Already?
The browse creation marks the end of the automated processes and the newly arrived Asset Files are now archived. In the case highlighted the Master Asset File is copied from the migration bucket where it arrived from the thawing Snowball to the long-term storage bucket and immediately set to the ‘Deep Archive’ class. The Master files in this case are being delivered from a service provider so have already undergone manual and automated Quality Control (QC) so those steps are not required. The Master file will be needed in due course to fulfil deliveries of content as orders are raised by broadcasters and distributors, but for now the browse file is all that is required for operations.
It’s never to early to archive! If master files are not needed in the near term these can be set to the Glacier or Deep Archive storage classes straight away.
Look our for our next BLAM Briefing where we’ll explore the process behind matching media to the inventory records and other metadata.